
RDS(Relational Database Service)란 무엇인가?
AWS에서 제공하는 관계형데이터베이스 서비스
클라우드에서 관계형 데이터베이스를 간편하게 설정, 운영 및 확장할 수 있습니다. 하드웨어 프로비저닝, 데이터베이스 설정, 패치 및 백업과 같은 시간 소모적인 관리 작업을 자동화하고, 비용 효율적이고 크기 조정 가능한 용량을 제공합니다. 사용자가 애플리케이션에 집중하여 애플리케이션에 필요한 빠른 성능, 고가용성, 보안 및 호환성을 제공할 수 있도록 지원해주는 서비스 입니다.
간단히 말하면 관계형 데이터베이스를 제공하는 AWS의 서비스이다. 유저가 사용하기 쉽도록 인프라 등을 자동화 시켜주고 유저들은 앤드포인트로 접속할 수 있는 데이터베이스를 제공받는다.
RDS 데이터베이스 엔진
- MySql
- PostgreSql
- MariaDB
- ORACLE
- SQLServer
- Amazone Aurora
RDS 특징
1. 관계형 데이터베이스를 제공하는 서비스
- Relational Database Service: 관계형 데이터베이스
- <-> NoSQL(DynamoDB, DocumentDB, ElasticCache) 차이점: 관계형 데이터베이스는 데이터베이스 안의 내용이 정형화 되어 있고 테이블 간 관계를 중심적으로 보는 DB이다.
2. 가상머신 위에서 동작
- 단 시스템에 직접 로그인 불가능 -> OS패치, 관리 등은 AWS의 역할, RDS는 Serverless 서비스가 아니다.
- 단 Aurora Serverless는 말 그대로 Serverless 서비스이다.
3. CloudWatch와 연동
- DB 인스턴스의 모니터링(EC2와 동일 ex: 디테일 모니터링, CPU, Storage 사용량)
- DB에서 발생하는 여러 로그(Error Log, General Log 등)을 확인 가능
4. 내부에서는 EC2 활용
- VPC 안에서 동작
- 기본적으로 Public IP를 부여하지 않아 외부에서 접근이 불가능하다.
- 설정에 따라 Public으로 오픈 가능하다(DNS 접근)
- 서브넷과 보안그룹지정 필요(이를 통해서 방화벽 역할을 수행한다.)
- EC2 타입의 지정 필요
- Storage는 EBS 활용
- EBS 타입의 선택 필요
- 생성시 EBS의 용량을 지정해서 생성(필요한 용량을 미리 지정해야 한다. 물론 추후에 용량 늘리는 것이 가능하다. Aurora의 경우에는 미리 지정하지 않고 사용한 양만큼만 지불한다.)
5. Parameter Group: Root 유저만 설정 가능한 DB의 설정값들을 모아 그룹화한 개념
- DB 클러스터에 파라미터 그룹을 적용시켜 설정값을 적용
- 마이너 버전 엔진 업데이트는 자동으로 업데이트 설정 가능
- 기타 업데이트(파라미터 그룹, EBS사이즈, 인스턴스 변경)의 경우 점검시간을 설정하여 특정 시간에 업데이트가 이루어질 수 있도록 설정 가능하다.
MySQL
90년대 중반에 개발된 MySQL은 시장에서 사용할 수 있는 최초의 오픈 DB중 하나이며 가장 널리 사용되고 있는 관계형 데이터베이스 관리 시스템(RDBMS: Relational DBMS)이다. MySQL은 단순 쿼리 처리 성능이 어떤 제품보다 압도적이며 이미 오래 사용되어 왔기 때문에 성능과 신뢰성 등에서 꾸준히 개선되어 온 것도 장점이다. 또한 MySQL은 오픈 소스이며, 다중 사용자와 다중 스레드를 지원하고 C언어, C++, JAVA, PHP 등 여러 프로그래밍 언어를 위한 다양한 API를 제공하고 있다.
MySQL은 유닉스, 리눅스, 윈도우 등 다양한 운영체제에서 사용할 수 있으며, 특히 PHP와 함께 웹 개발에 자주 사용된다. 그러나 MySQL은 오픈 소스 라이센스를 따르기는 하지만, 상업적으로 사용할 때는 상업용 라이센스를 구입해야만 한다.
특징
- SQL 문법 기반
- 거의 모든 운영체제에서 사용 가능
- MySQL 데이터베이스는 무료
- 처리 속도가 빠르고 대용량 데이터 처리에 용이
- 설치 방법과 사용법이 쉬움
- 보안성이 우수
- 다중 동시 데이터 베이스 사용자 지원
MariaDB
발전하던 MySQL이 2010년에 썬마이크로시스템즈와 오라클이 합병되면서 많은 MySQL 개발자들은 썬마이크로시스템즈을 떠나며 본인만의 프로젝트를 진행하게 된다. 이 중 MySQL의 창시자인 몬티 와이드니어가 만든 프로젝트가 바로 MariaDB이다.
MariaDB는 MySQL 데이터베이스 시스템을 기반으로 fork한 서비스로 MySQL의 개선된 버전이다. 그래서 MariaDB와 MySQL의 호환성은 매우 높다. (공식문서 참고) 또한 MySQL에서 찾을 수 없는 수많은 내장된 강력한 기능과 많은 유용성, 보안 및 성능 개선사항이 함께 제공된다.
- mysql은 주로 MyISAM, InnoDB 두가지 스토리지 엔진중 하나를 사용한다.
특징
- MySQL을 만든 개발자가 만든 RDBMS
- 그래서 MySQL과 매우 유사
- 상업용으로도 무료로 제공
- 많은 운영 체제에서 실행 가능
- MySQL에서 사용할 수 없는 많은 작업과 명령을 제공하여 몇몇 단점을 제거 및 대체
Oracle
특징
- 대부분의 운영체제를 지원
- 분산처리를 통해 효율성 증대
- DBMS 실행 컴퓨터 / 서버 역할 컴퓨터 / DB응용 프로그램 실행 컴퓨터를 다르게 분산처리
- 대규모 데이터베이스와 영역 관리
- 고가의 HW를 효율적으로 활용할 수 있도록 영역 사용을 완벽하게 제어
- 다중 동시 데이터 베이스 사용자 지원
- 여러 사용자가 동일한 데이터에서 작동하는 다양한 데이터베이스 응용 프로그램을 실행하도록 지원하여 데이터 경합을 최소화하고 데이터 동시성을 보장
- 데이터 경합(row level locking) : 데이터 경쟁. 한 사용자가 데이터를 변경하려고 접근할 때 데이터에 lock이 걸리는 것
- 데이터 동시성 : 다수의 사용자가 동시에 접근 가능
- 접속성
- 서로 다른 유형의 컴퓨터와 운영체제가 네트워크를 통해 정보를 공유하도록 함
- 고성능 트랜잭션 처리
- 다른 데이터베이스보다 고성능의 트랙잭션을 처리
PostgreSQL
특징
- 대용량 데이터 처리를 위한 기능 구현됨
- 다양한 운영체제 지원
- DB 보안을 위해 데이터 암호화, 접근 제어, 접근 감시 3가지로 구성됨
- 여러 언어 지원
- 신뢰성과 안정성이 매우 높음
- 오픈 소스이기 때문에 무료로 사용 가능
mysql은 주로 MyISAM, InnoDB 두가지 스토리지 엔진중 하나를 사용한다.
MyISAM
- MyISAM은 Table과 Index를 각각 다른 파일로 관리
- Read Only기능이 많은 서비스일 수록 MyISAM엔진이 효율적
InnoDB
InnoDB는 MySQL의 데이터베이스 엔진입니다.
MySQL의 모든 바이너리에 내장이 되어 있습니다.
트랜잭션을 지원합니다. 그렇기 때문에 트랜잭션 세이프 스토리지 엔진입니다.
- 트랜잭션 처리가 필요하고 대용량의 데이터를 다루기 위해서는 InnoDB가 효율적
- InnoDB는 Tablespace 개념을 사용한다.
- innodb_system 이라는 테이블스페이스로 기본적으로 구성된다.
- mysql 설치시 디폴트로 ibdata 파일이 있음
- 환경변수 : innodb_data_file_path, innodb_data_home_dir
장점
- 우수한 성능
다수의 사용자가 동시 접속을 할 수 있고, 대용량의 데이터를 처리할 수 있습니다.
데이터 테이블과 인덱스를 테이블 스페이스에 저장을 하고 있고, 테이블 스페이스는 파일과 파티션으로 구성되어 있습니다.
그렇게 때문에 성능이 우수합니다. - 장애 복구 기능
단순하게 장애 복구를 하지 않고, 논리적으로 장애 복구를 수행합니다.
데이터 무결성에 대한 보장
InnoDB의 설계를 할 때, 데이터 무결성에 대해서 중점을 두었습니다.
단점
- Deadlock 발생
NODE간의 데이터 체크로 인하여, Deadlock 발생 가능성이 존재합니다 - 많은 자원 소모
대용량 처리를 하게 된다면, 순간적으로 많은 자원을 소모합니다. - 데이터 복구의 어려움
단순하게 파일 백업으로 복구를 하는게 아니라, 특정한 방법을 사용하여 복구를 수행합니다.
특징
- InnoDB는 PK를 기준으로 클러스터링
따라서, 다른 보조 Index보다 PK를 우선적으로 탐색하는 경향이 존재 - Oracle의 아키텍쳐 적용
MVCC(Multi version Concurrency Control) 및 테이블 스페이스 등 오라클에서 주로 사용되는 개념들이 적용됨
MVCC : 락을 걸지않고 작업을 수행함으로써, 다른 트랜잭션이 갖고있는 락을 기다리지않고 읽기작업이 가능
InnoDB 구조 및 아키텍처
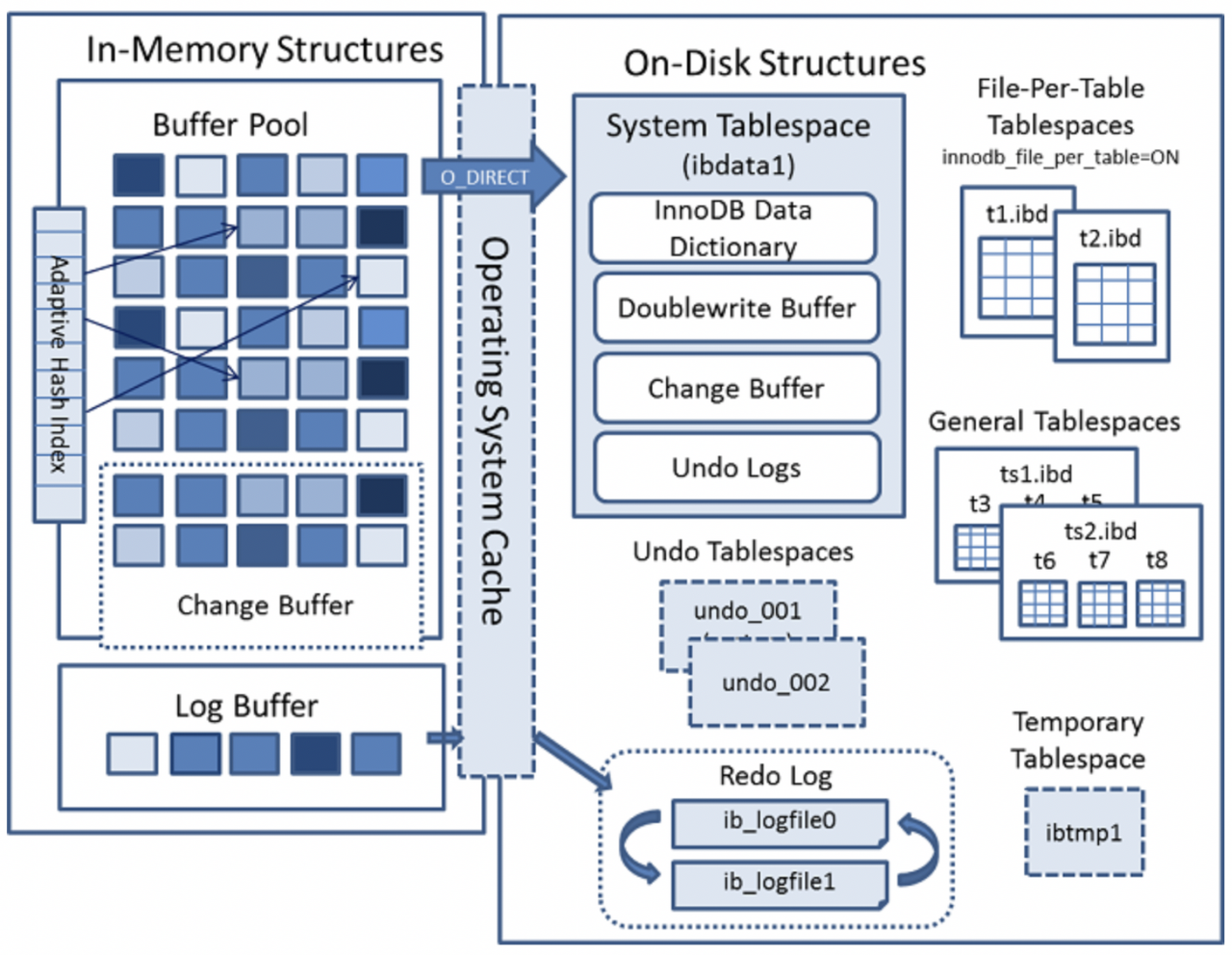
InnoDB는 In-memory 구조로, 데이터와 인덱스를 메모리에 캐싱하기 위한 버퍼 풀이라는 저장 영역을 유지 관리한다.
주요 구성으로는 Buffer Pool, Log Buffer, Change Buffer 등으로 구성된다.
✔ Buffer Pool
InnoDB가 액세스할 때 테이블 과 인덱스 데이터를 캐시하는 메인 메모리영역입니다.
해당 영역은 메모리로부터 데이터를 직접 처리할 수 있게하여 처리속도를 향상시킵니다.
dedicated server의 경우, 물리 메모리의 최대 80%까지 버퍼풀이 할당됩니다.
효과적으로 읽기 작업을 하기 위해서 버퍼 풀은 여러 행을 보유할 수 있는 페이지들로 나눠집니다.
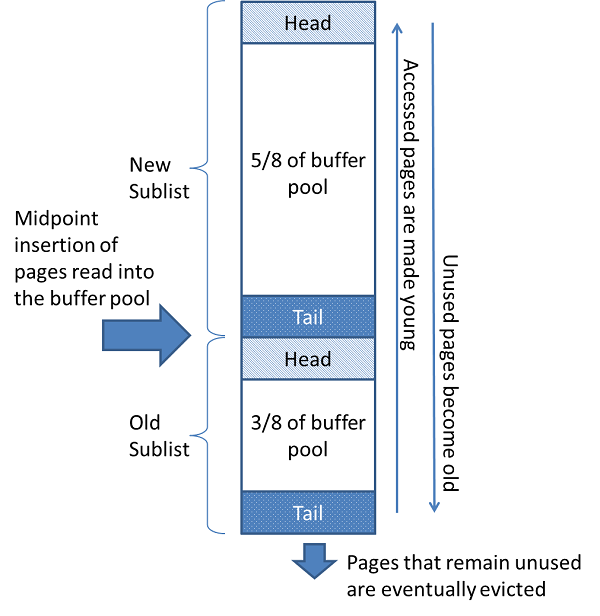
위와 같은 LRU 방식으로 버퍼풀에 새로운 페이지를 추가시킨다.
- Head(상단) : 최근에 액세스한 새로운 page의 서브리스트
- Tail(하단) : 비교적 덜 최근에 액세스한 page의 서브리스트
LRU 방식을 활용하여 자주 액세스하는 데이터를 메모리에 유지시킨다.
트랜잭션(Transaction)
트랜잭션은 데이터의 정합성을 보장하기 위한 기능입니다.
트랜잭션은 꼭 여러 개의 변경 작업을 수행하는 쿼리가 조합됐을때만 의미있는 개념은 아닙니다.
트랜잭션은 논리적인 작업 셋 자체가 100% 적용되거나(COMMIT) 또는 아무것도 적용되지 않아야 함(ROLLBACK)을 보장해주는 것입니다.
이러한 트랜잭션은 ACID라 하는 원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability)을 보장해야 합니다.
- 원자성(Atomicity): 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공하거나 혹은 모두 실패해야 합니다.
- 일관성(Consistency): 모든 트랜잭션은 일관성있는 데이터베이스 상태를 유지해야 합니다. 예를 들면 데이터베이스에서 정한 무결성 제약 조건을 항상 만족해야 합니다.
- 격리성(Isolation): 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리해야 합니다. 예를 들면 동시에 같은 데이터를 수정하지 못하도록 해야 합니다. 격리성은 동시성과 관련된 성능 이슈로 인해 격리 수준을 선택할 수 있습니다.
- 지속성(Durability): 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 합니다. 중간에 시스템에 문제가 발생하더라도 데이터베이스 로그 등을 사용해서 성공한 트랜잭션 내용을 복구해야 합니다.
트랜잭션은 원자성, 일관성, 지속성을 보장하는데 문제는 격리성입니다. 트랜잭션간에 격리성을 완벽히 보장하려면 동시에 처리되는 트랜잭션을 거의 차례대로 실행을 해야합니다. 하지만 이렇게 처리를 하면 처리 성능이 매우 나빠지게 됩니다. 이러한 문제로 인해 ANSI 표준은 트랜잭션의 격리 수준을 4단계로 나누어 정의하고 있습니다.
트랜잭션의 격리 수준(Isolation Levels)
동시에 여러 트랜잭션이 처리될 때, 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있도록 허용할지 말지를 결정하는 것입니다.
우선 Transaction에서 사용 되는 개념이며 SQL은 4개의 Isolation level을 정의하고 있으며 각 Storage Engine 혹은 DBMS 마다 조금씩 다르게 구현 되어 있습니다.
격리 수준은 다음과 같이 4가지로 정의할 수 있습니다.
- READ UNCOMMITTED(커밋되지 않은 읽기)
- READ COMMITTED(커밋된 읽기)
- REPEATABLE READ(반복 가능한 읽기)
- SERIALIZABLE(직렬화 가능)
순서대로 READ UNCOMMITTED의 격리 수준이 가장 낮고 SERIALIZABLE의 격리 수준이 가장 높습니다.
격리 수준이 높아질수록 MySQL 서버의 처리 성능이 많이 떨어질 것으로 생각하는 사용자가 많은데, 사실 그렇지는 않습니다.
SERIALIZABLE 격리 수준이 아니라면 크게 성능의 개선이나 저하는 발생하지 않습니다.
아래 표는 트랜잭션 격리 수준에 따라 발생하는 문제점입니다.
| 격리 수준 | DIRTY READ | NON-REPEATABLE READ | PHANTOM READ |
| READ UNCOMMITTED | O | O | O |
| READ COMMITTED | O | O | |
| REPEATABLE READ | O(InnoDB는 발생 X) | ||
| SERIALIZABLE |
위(READ UNCOMMITTED)쪽으로 갈 수록 격리 수준이 낮아지는데 격리 수준이 낮을수록 더 많은 문제가 발생합니다.
트랜잭션 격리 수준에 따라 발생하는 문제점에 대해 알아보겠습니다.
SQL-92 또는 SQL-99 표준에 따르면 REPEATABLE READ 격리 수준에서는 PHANTOM READ가 발생할 수 있으나 InnoDB에서는 독특한 특성 때문에 REPEATABLE READ 격리 수준에서도 PHANTOM READ가 발생하지 않습니다.
오라클의 경우 주로 READ COMMITTED을, MySQL의 경우 REPEATABLE READ를 주로 사용합니다.
일반적인 온라인 서비스 용도의 데이터베이스는 READ COMMITTED와 REPEATABLE READ 둘 중 하나의 전략을 사용합니다.
1. READ UNCOMMITTED (커밋되지 않은 읽기)
- Transaction은 uncommitted 결과를 볼 수 있다.
- 이 단계에서 너가 정말 정말 좋은 의도로 개발을 했지만 많은 문제가 발생할 수 있다.
- 이 단계는 거의 실용적이지 않다. 왜냐하면, 성능이 다른 레벨들보다 좋지 않기 때문이다.
- uncommitted data를 읽는 것은 'dirty read' 라고도 알려져 있다.

Transaction 이 끝나지 않은 상황에서 각기 다른 Transaction이 변경한 내용에 대한 조회가 가능합니다. 데이터베이서의 일관성을 유지할 수 없습니다
Transaction1이 수행중에 Transaction2가 값을 변경할 경우 Transaction1이 다시 조회를 하는 시점에 이미 Transaction2가 값을 변경하였기 때문에 아무개에서 개발자로 값이 변경되어 조회가 됩니다.
이처럼 어떠한 트랜잭션에서 처리한 작업이 완료되지 않았음에도 불구하고 다른 트랜잭션에서 볼 수 있게 되는 현상을
더티 리드(Dirty Read)라 하고, 더티 리드가 허용되는 격리 수준이 READ UNCOMMITTED입니다.
더티 리드 현상은 데이터가 나타났다가 사라졌다 하는 현상을 초래할 수 있으므로 개발자와 사용자를 상당히 혼란스럽게 만들 것입니다. 또한 더티 리드를 유발하는 READ UNCOMMITTED 격리 수준은 RDBMS 표준에서는 트랜잭션의 격리 수준으로 인정하지 않을 정도로 정합성에 문제가 많은 격리 수준입니다. 따라서 MySQL을 사용한다면 최소 READ COMMITTED 이상의 격리 수준을 사용할 것을 권장합니다.
2. READ COMMITED (커밋된 읽기)
- DBMS의 default isolation level 이다. (MySQL 제외하고…)
- 트랜잭션 시작하고 이미 commit 된 변화를 볼 수 있지만, commit 완료 전까지는 확인이 불가하다.
- 'nonrepeatable read' : 하나의 트랜잭션이 같은 행을 두 번 읽었을 때, 두 번째 읽기에서 첫 번째와 다른 결과를 얻는 경우를 말합니다. 이는 다른 트랜잭션이 그 행을 수정하거나 삭제했을 때 발생할 수 있습니다.
조회 시 데이터에 대한 Shared lock이 됩니다. Read Uncommitted와 다르게 Commit이 이루어진 데이터가 조회됩니다. 하지만 어떠한 사용자가 A라는 데이터를 B라는 데이터로 변경하는 동안 다른 Transaction은 접근할 수 없어 대기하게 됩니다.

1) Transaction2가 Update를 하게됩니다.
2) 아직 커밋하지 않아 Transaction1은 Select를 하지 못하고 대기하게 됩니다.
3) Transaction2가 Commit명령어를 날리게됩니다.
4) 이제 Transaction2는 조회가 가능합니다.
언두 레코드는 InnoDB의 시스템 테이블 스페이스의 언두 영역에 기록이 되는데, 언두 레코드는 트랜잭션의 격리 수준을 보장하기 위한 용도뿐 아니라 트랜잭션의 ROLLBACK에 대한 복구에도 사용이 됩니다.★ 언두(Undo) 로그 ★언두 영역은 UPDATE 문장이나 DELETE와 같은 문장으로 데이터를 변경했을 때 변경되기 전의 데이터(이전 데이터)를 보관하는 곳입니다. 예를 들어 다음 쿼리를 살펴보겠습니다.
MySQL > UPDATE member SET name = '이주현' WHERE member_id = '5';
위 문장이 실행되면 트랜잭션을 커밋하지 않아도 실제 데이터 파일 내용은 "이주현"으로 변경이 됩니다. 그리고 변경되기 전의 값이 "홍길동"이라면 언두 영역에는 "홍길동"이라는 값이 백업이 되는 것입니다. 이 상태에서 만약 사용자가 커밋하게 되면 현재 상태(이주현)가 그대로 유지되고, 롤백하게 된다면 언두 영역의 백업된 데이터(홍길동)를 다시 데이터 파일로 복구합니다.
이러한 언두의 데이터는 크게 두 가지 용도로 사용이 됩니다.
1) 트랜잭션의 롤백 대비용
2) 트랜잭션의 격리 수준을 유지하면서 높은 동시성을 제공
3. REPEATABLE READ (반복 가능한 읽기)
- REPEATABLE READ 는 READ UNCOMMITTED 가 허락한 문제들을 해결 한다.
- 같은 Transaction 안에서 Transaction이 읽고 있는 어느 rows은 그 다음에 읽어도 같은 것을 볼 것을 보장하지만, 이론적으로 phantom reads에 대해서 또다른 문제가 있을 수 있다.
(Phantom read : 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다가 안보였다가 하는 현상) - InnoDB와 XtraDB는 multiversion concurrency control (다중 버전 동시성 제어)로 phantom read를 해결한다.
- MySQL의 기본 Transaction 고립 레벨

Transaction이 범위내에서는 조회한 데이터의 내용이 항상 동일함을 보장해줍니다.
1) Transaction1이 Select시점에 아무개가 조회됩니다.
2) Transaction2가 Update후 Commit을 시행하였지만 Update가 안됩니다. 그러나 Insert는 됩니다.
3) Transaction1이 다시 조회 해봐두 Transaction2가 Commit이 되지 않았기 때문에 아무개로 조회됩니다. 하지만 Insert한 동네개발자는 조회됩니다.
4) Transaction1이 종료되면 다시 Commit이 이루어지기 때문에 개발자로 조회가 됩니다.
InnoDB 스토리지 엔진은 트랜잭션이 ROLLBACK될 가능성에 대비해 변경되기 전 레코드를 언두(Undo) 영역에 백업해두고 실제 레코드 값을 변경합니다. 이러한 변경 방식을 MVCC(Multi Version Concurrency Control)이라고 합니다
★ 언두(Undo) 로그 ★
언두 영역은 UPDATE 문장이나 DELETE와 같은 문장으로 데이터를 변경했을 때 변경되기 전의 데이터(이전 데이터)를 보관하는 곳입니다.
언두 레코드는 InnoDB의 시스템 테이블 스페이스의 언두 영역에 기록이 되는데, 언두 레코드는 트랜잭션의 격리 수준을 보장하기 위한 용도뿐 아니라 트랜잭션의 ROLLBACK에 대한 복구에도 사용이 됩니다.
READ COMMITTED 격리 수준 또한 MVCC를 이용해 COMMIT되기 전의 데이터를 보여주나 REPEATABLE READ와 READ COMMITTED의 차이는 언두 영역에 백업된 레코드의 여러 버전 가운데 몇 번째 이전의 버전까지 찾아 들어가야 하는지에 있습니다.
MVCC(Multi Version Concurrency Control) - 잠금을 사용하지 않는 일관된 읽기를 제공
MVCC는 다중 버전 병행수행 제어의 약자로 DBMS에서는 쓰기(Write) 세션이 읽기(Read) 세션을 블로킹하지 않고, 읽기 세션이 쓰기 세션을 블로킹하지 않게 서로 다른 세션이 동일한 데이터에 접근했을 때 각 세션마다 스냅샷 이미지를 보장해주는 메커니즘이는 RDBMS에서 동시성을 높이기 위해 등장한 기술로, 소수의 전산실 운영자들이 서버 컴퓨터를 사용하던 시절에는 MVCC가 선택사항이었지만 인터넷이 보편화되고 온라인으로 업무를 처리하는 시대에서는 DBMS를 선택하는데 있어 MVCC가 가장 중요한 요소가 됐다.
4. SERIALZABLE (직렬화 가능)
- 최상위 고립 레벨의 SERIALIZABLE 은 phantom read를 해결하기 위해서 충돌하지 않도록 Transactio들에게 강제로 명령을 한다.
- 읽은 모든 row에 락을 걸고, 이 단계에서 많은 타임아웃과 락 논쟁이 발생할 수 있다.

말 그대로 직렬화를 이야기합니다. 그래서 모든 동작이 직렬화 되어 작동합니다. Repeatable Read와 다르게 Insert를 하여도 작동하지 않게 됩니다.
정리
트랜잭션 격리 수준
- READ UNCOMMITTED: 트랜잭션내에서 커밋하지 않은 데이터에 다른 트랜잭션의 접근이 가능
- READ COMMITTED: 트랜잭션내에서 커밋된 데이터만 다른 트랜잭션이 읽는 것을 허용
- REPEATABLE READ: 트랜잭션 내에서 한 번 조회한 데이터를 반복해서 조회해도 결과는 동일
- SERIALIZABLE: 가장 엄격한 격리 수준으로 완벽한 읽기 일관성 모드 제공
격리 수준에 따라 발생할 수 있는 문제점
- DIRTY READ: 어떠한 트랜잭션에서 처리한 작업이 완료되지 않았음에도 불구하고 다른 트랜잭션에서 볼 수 있게 되는 현상
- NON-REPEATABLE READ: 동일한 SELECT 쿼리를 실행했을 때 항상 같은 결과를 보장해야 한다는 "REPEATABLE READ" 정합성에 어긋나는 현상
- PHANTOM READ: 한 트랜잭션내에서 동일한 쿼리를 두 번 수행했는데, 첫 번째 쿼리에서 존재하지 않던 유령(Phantom) 레코드가 두 번째 쿼리에서 나타나는 현상
연관된 글:
참고 :
https://sanggi-jayg.tistory.com/12
https://zzang9ha.tistory.com/381
https://velog.io/@byu0hyun/mysql-InnoDB%EB%9E%80
https://letitkang.tistory.com/155
https://benlee73.tistory.com/178
https://loosie.tistory.com/366
https://dev.classmethod.jp/articles/for-beginner-rds-explanation/
https://velog.io/@ghldjfldj/AWS-RDS%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80-zuaaizv4
'개발 > DB' 카테고리의 다른 글
| [Oracle] dual 테이블 (0) | 2023.03.17 |
|---|---|
| [Java] Java의 동작 원리 - Garbage Collection (0) | 2023.03.16 |
| [DB] ANSI 표준 (0) | 2023.03.09 |
| [DB] mybatis ibatis 비교 및 Dynamic Query (0) | 2023.03.09 |
| [DB] rdb(관계형 데이터 베이스) (0) | 2023.02.21 |